Co-Me: Confidence-Guided Token Merging for Visual Geometric Transformers
Yutian Chen1,2, Yuheng Qiu1, Ruogu Li1,
Ali Agha2, Shayegan Omidshafiei2, Jay Patrikar2, Sebastian Scherer1,2
Ali Agha2, Shayegan Omidshafiei2, Jay Patrikar2, Sebastian Scherer1,2


1
2
Abstract
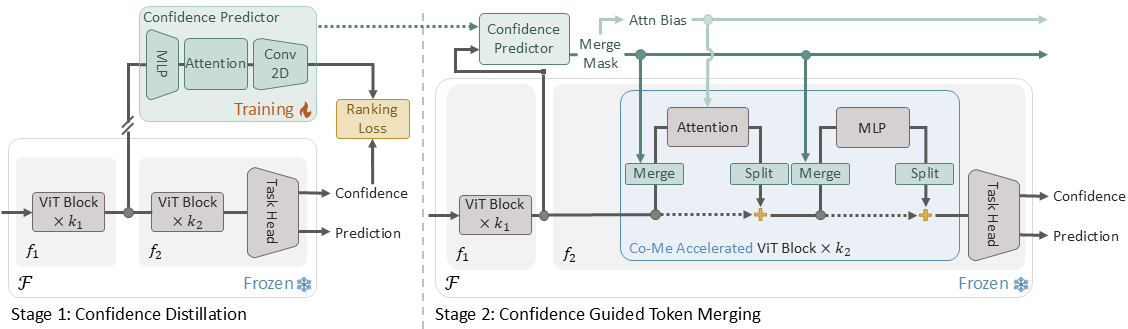
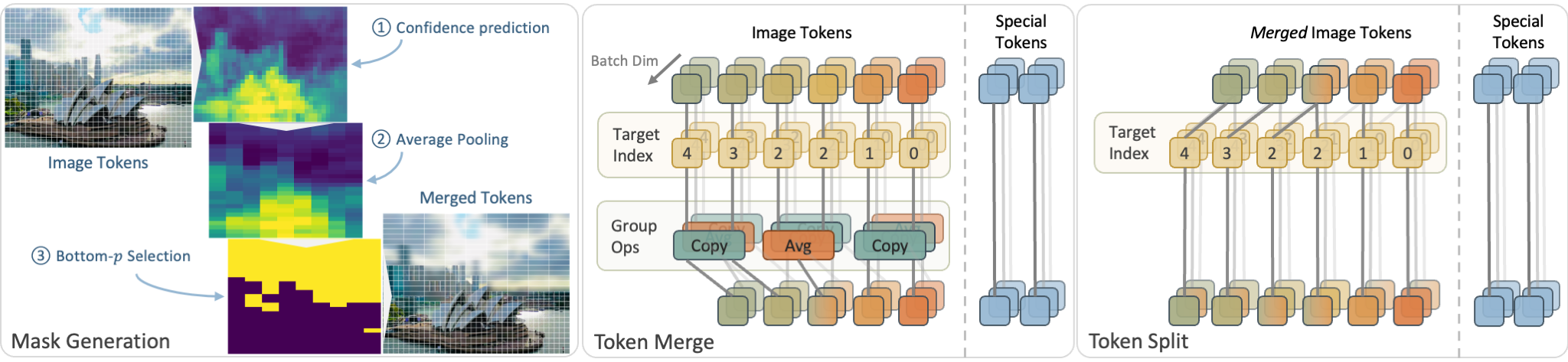
We propose Confidence-Guided Token Merging (Co-Me), an acceleration mechanism for visual geometric transformers without retraining or finetuning the base model. Co-Me employs a light-weight distilled confidence predictor to rank tokens and selectively merge low-confidence ones, effectively reducing computation while maintaining spatial coverage. Compared to similarity-based merging or pruning, the confidence signal in Co-Me reliably indicates regions emphasized by the transformer, enabling substantial acceleration without degrading performance. Co-Me applies seamlessly to various multi-view and streaming visual geometric transformers, achieving speedups that scale with sequence length. When applied to VGGT and MapAnything, Co-Me achieves up to $11.3\times$ and $7.2\times$ speedup, making visual geometric transformers practical for real-time 3D perception and reconstruction.
Qualitative Comparison


Original VGGT
Co-Me Accelerated


Original VGGT
Co-Me Accelerated


Original VGGT
Co-Me Accelerated


Original VGGT
Co-Me Accelerated


Original MapAnything
Co-Me Accelerated


Original MapAnything
Co-Me Accelerated


Original MapAnything
Co-Me Accelerated


Original MapAnything
Co-Me Accelerated
Methods
Citation
@misc{chen2025comeconfidenceguidedtokenmerging,
title={Co-Me: Confidence-Guided Token Merging for Visual Geometric Transformers},
author={Yutian Chen and Yuheng Qiu and Ruogu Li and Ali Agha and Shayegan Omidshafiei and Jay Patrikar and Sebastian Scherer},
year={2025},
eprint={2511.14751},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2511.14751},
}